SiFiSinger: SiFi-GAN を内包した歌唱音声合成
☆芦田 裕飛,中鹿 亘
概要: 歌唱音声合成は,可能な限り基本周波数(f0)の制御と品質の双方が達成できることが望ましい.
例えば,テキスト音声合成においては End-to-End モデルのVITS [1]やJETS[2]などが成功を収めているが,あくまでテキスト音声合成のためで,f0 の制御性は不足している.
歌唱音声合成の既存手法であるXiaoiceSing [3]は,WORLD ボコーダを用いることから,f0 の制御性は高いが,品質に限界がある.
歌唱音声合成が End-to-End 化できるのであれば,品質の向上が見込めるが,f0 の制御性を保ったまま End-to-End 化することについては議論されていなかった.
そこで,品質改善と f0 の制御性を両立できるようにするには学習可能で f0 制御性もあるボコーダとして SiFi-GAN [4]を活用し,さらに End-to-End 化する SiFiSinger を提案する.
提案手法によって,品質向上と f0 の制御性をおおよそ両立可能であることを実証した.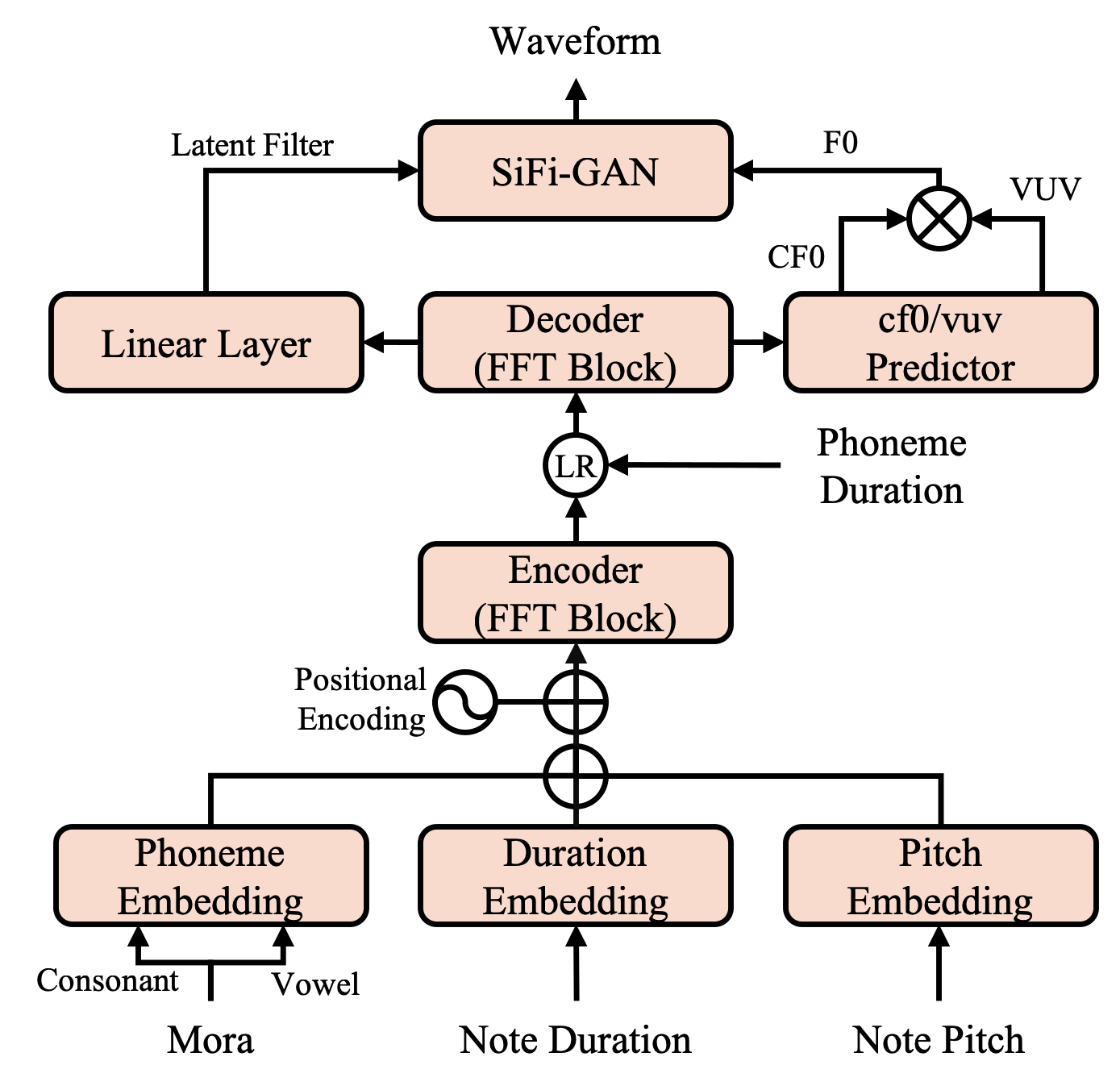
例えば,テキスト音声合成においては End-to-End モデルのVITS [1]やJETS[2]などが成功を収めているが,あくまでテキスト音声合成のためで,f0 の制御性は不足している.
歌唱音声合成の既存手法であるXiaoiceSing [3]は,WORLD ボコーダを用いることから,f0 の制御性は高いが,品質に限界がある.
歌唱音声合成が End-to-End 化できるのであれば,品質の向上が見込めるが,f0 の制御性を保ったまま End-to-End 化することについては議論されていなかった.
そこで,品質改善と f0 の制御性を両立できるようにするには学習可能で f0 制御性もあるボコーダとして SiFi-GAN [4]を活用し,さらに End-to-End 化する SiFiSinger を提案する.
提案手法によって,品質向上と f0 の制御性をおおよそ両立可能であることを実証した.
図1: SiFiSingerのアーキテクチャ
デモ音声
index | 自然音声 | Xiaoice+SiFi | Xiaoice+SiFi(GTラベル) | SiFiSinger(提案手法) | SiFiSinger(提案手法/GTラベル) |
|---|---|---|---|---|---|
0 | |||||
1 | |||||
2 | |||||
3 | |||||
4 | |||||
5 | |||||
6 | |||||
7 | |||||
8 | |||||
9 | |||||
10 | |||||
11 | |||||
12 | |||||
13 | |||||
14 | |||||
15 | |||||
16 | |||||
17 | |||||
18 | |||||
19 | |||||
20 | |||||
21 | |||||
22 | |||||
23 | |||||
24 | |||||
25 | |||||
26 | |||||
27 | |||||
28 | |||||
29 | |||||
30 | |||||
31 | |||||
32 | |||||
33 | |||||
34 | |||||
35 |
参考文献:
- [1] Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech
- [2] JETS: Jointly Training FastSpeech2 and HiFi-GAN for End to End Text to Speech
- [3] XiaoiceSing: A High-Quality and Integrated Singing Voice Synthesis System
- [4] Source-Filter HiFi-GAN: Fast and Pitch Controllable High-Fidelity Neural Vocoder